Testing code is hard. In the software engineering circles I frequent (mostly the android community), I hear a good amount of conversation around best practices for testing. But most of these conversations are just bikeshedding about which libraries and tools to use — I rarely hear people focus on the most important questions about tests: are your tests valuable? Are they worth the effort you put into them?
If you’re testing the wrong thing, your tests are not valuable no matter whether you use the fanciest libraries. If you need to change your tests when you simply refactor your module, your tests might be slowing the team down more than they’re helping. If you’re forcing code coverage requirements without creating a culture of writing helpful tests, you’ll end up with a lot of low-quality tests that simply repeat the code that they’re testing. At best, these types of tests are unhelpful productivity suckers; at worst, these tests can give you false confidence and cause you to release buggy code.
Today I want to present one pattern that can help avoid some of these problems and make tests more valuable: using fakes instead of mocks. I’ll try to make this platform- and language-agnostic, focusing on fundamental patterns teams can bring into their unique codebases and cultures.
TL;DR
- Using mocks means you’re repeating yourself a lot and writing tests that don’t match an ever-changing reality.
- Sharing fakes between tests, while more work upfront, can help you write tests that:
- are more concise
- are easier to write and maintain
- give you more confidence that your code is correct
Why test?
Let’s take a step back first and remind ourselves why we write tests. Automated tests are valuable because:
- They give a team confidence its code is correct before a release
- They help developers find bugs early in development, if successful test runs are required before merging code
- They nudge developers to write better-architected code to make writing tests easier
- They force developers to think through their code
These benefits apply across platforms, languages, industries, and business areas. They matter more when a project’s tolerance for risk is low (e.g. in finance, since people don’t seem to like it when you send their money to the wrong place), but they still apply everywhere.
Test structure
Now let’s remind ourselves how tests are constructed. We have our module under test, which takes some input, uses some dependencies, and produces some output:
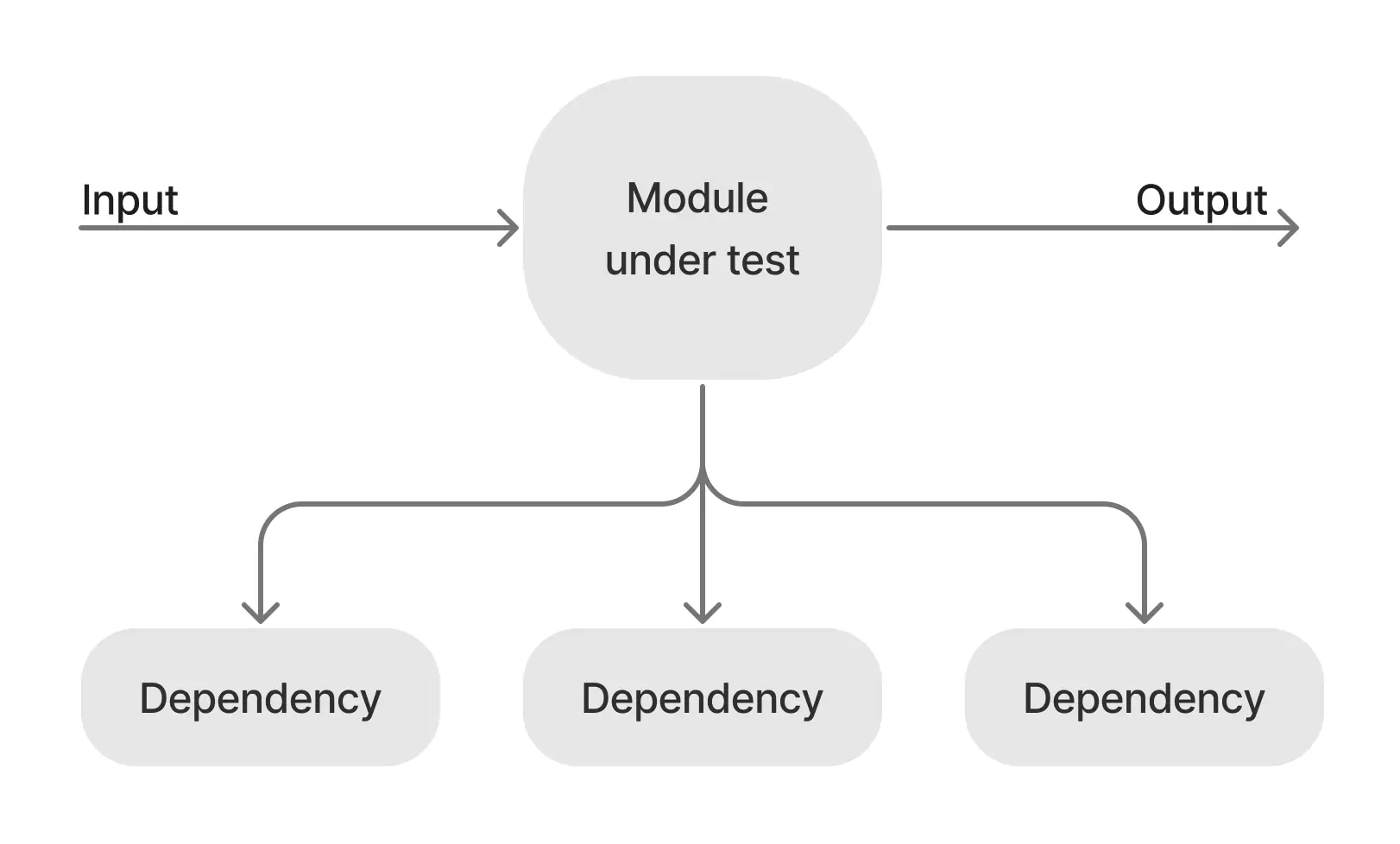
Now when we want to test this module, we usually provide some test input, swap out the dependencies for ones we can control, and make some assertions about the output:
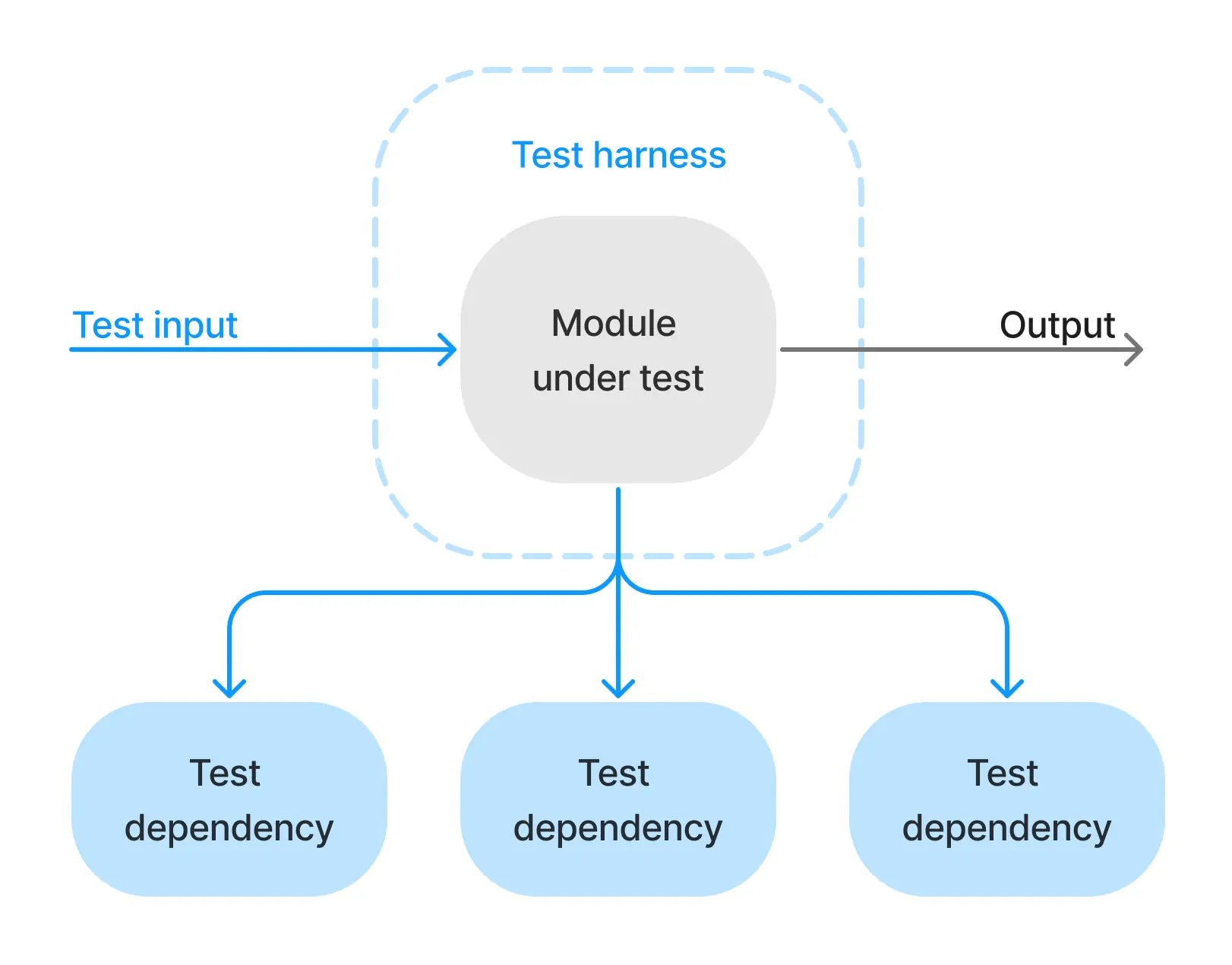
In this post, we’re going to focus on the importance of properly replacing dependencies.
The problem with mocks
One popular way to replace dependencies in tests, especially in the android community, is to use a mocking library like Mockito or MockK. Mocking dependencies like this is great for lightly testing modules with a few simple dependencies, but quickly breaks down when testing larger modules with multiple, complex dependencies.
The reason is that, when mocking, we write all our configuration inside each test.
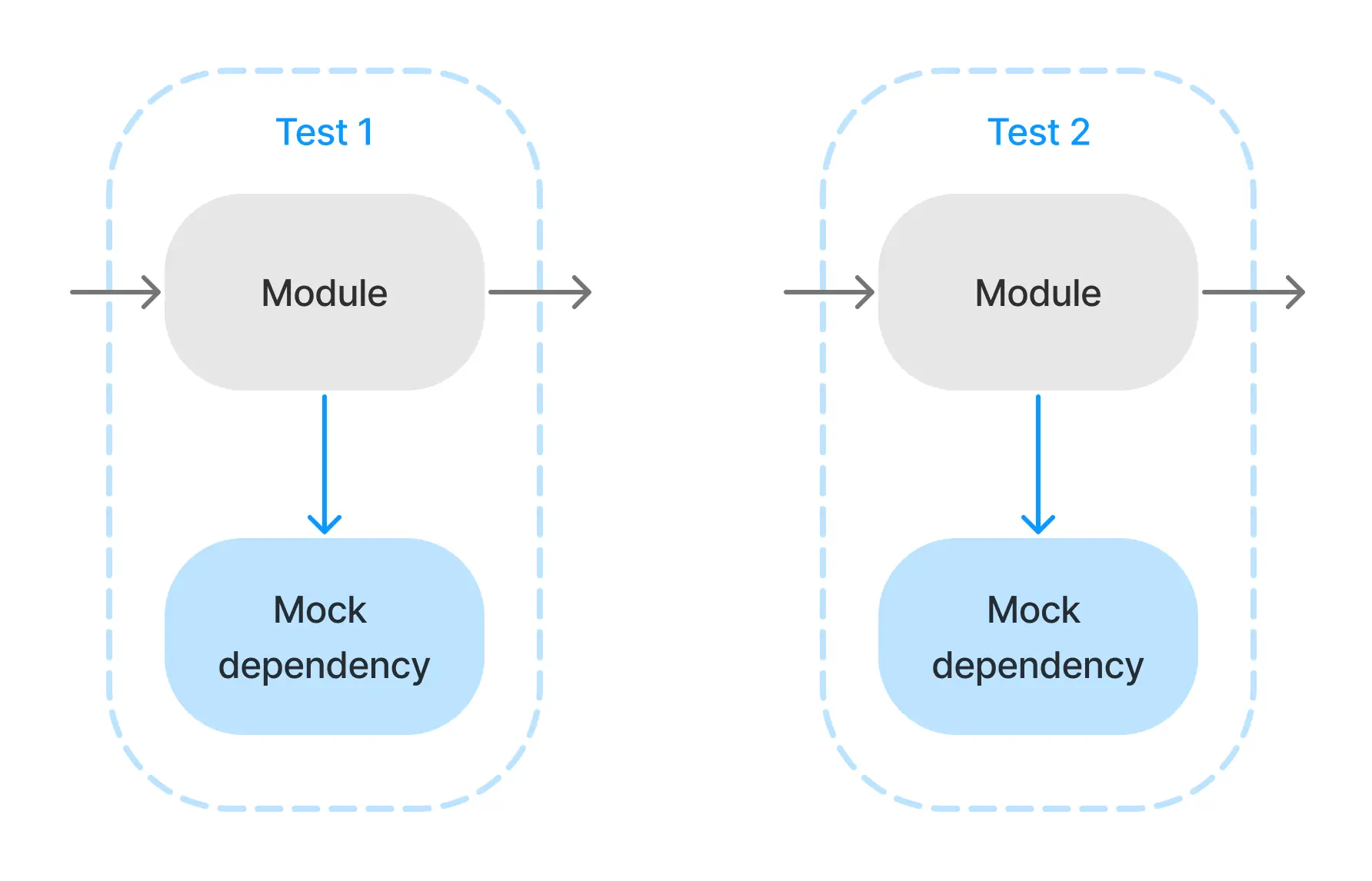
Now, imagine we change the API or behavior of one of these dependencies. We now have to change every test we’ve ever written that mocks that dependency. This means more maintenance cost at best, and incorrect tests at worst.
I want to emphasize that last point for a moment. Tests with mocked dependencies can’t be relied on, because they don’t reliably test the module’s interaction with its dependencies.
So how can we fix this?
The value of fakes, aka reusing mocks between tests
One way to fix this problem is to define the desired modules’ behavior in shared mocks and reuse them in multiple tests. So, when the behavior or API of these dependencies change, we update our shared mocks and all of our tests that depended on the old behavior fail!
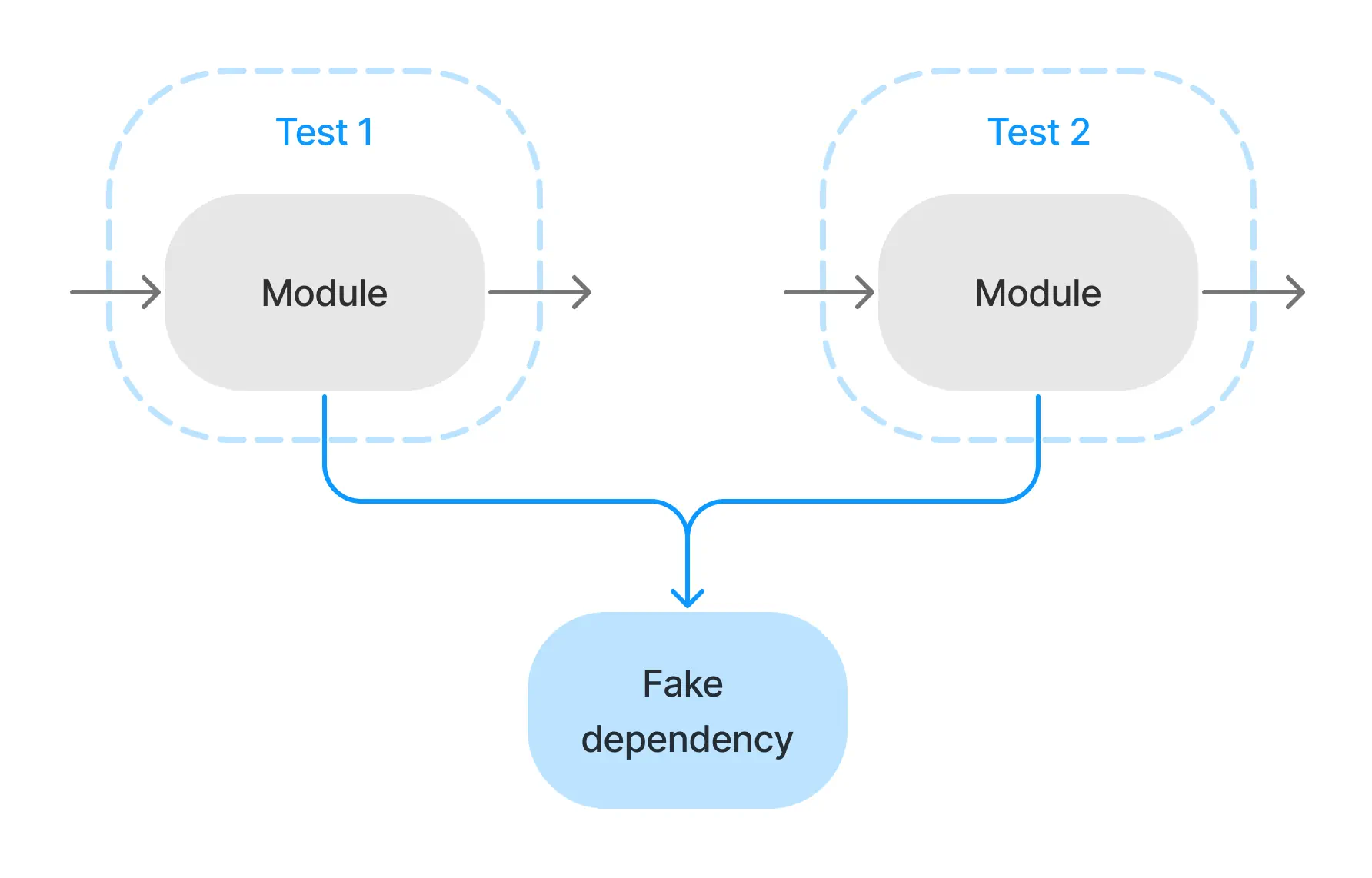
In this case, failure is a good thing, because those tests are testing the wrong thing and giving us false confidence that our code is correct and ready to ship. Also note that we don’t (necessarily) need to change any of our tests when this dependency’s behavior or API changes, and we can instead focus on fixing the real behavior of our dependent modules.
A shared mock like one of these is usually called a “fake,” since it fakes a module’s behavior. We still cut off the fake’s dependencies as to avoid e.g. making a real network call, moving real money, or taking a real picture. And they’re best built avoiding the mocking libraries altogether.
Using fakes can make your test suite more correct, more complete, and easier to maintain than “pure” unit tests relying on one-off mocks.
Tips for writing effective fakes
Like any other pattern, it can take time to learn the best practices of testing with fakes. Below are some tips from my personal experience implementing this pattern, but let me know if you have any further ideas by sending me a message.
We want these objects to be reusable, so we have a couple considerations to make:
- Any customization options on fakes should be concise.
- Fakes should be flexible enough to work in most tests (you can always add more options later, start off simple).
- Fakes’ simplicity should roughly match how often they’re used in other code. Simpler is always better, but if a module is used in many places, it’s worth investing more time and complexity into its fake.
Not to turn this into a listicle, but here are some suggestions for following these principles:
- Fakes likely mean using more interfaces with
Real*andFake*implementations. It’s worth standardizing a naming scheme for these throughout the codebase, but don’t spend too long thinking about it. - Fakes usually also mean sets of fake data: fake users, fake database responses, fake error messages, etc. It’s worth investing in these and getting them right for your use cases.
- You should consider your testing API as carefully as you consider your module’s API. Be careful not to recreate a mock, where every facet of the behavior is defined in every test. Aim for test customizations to read naturally, closer to “log in successfully” than “return a 200 with this object.”
- You should provide sensible defaults to limit the amount of customization needed in most tests.
- You can front-load the work to create fakes by requiring that fakes be written alongside new modules. That way they’re there when you need them.
- As silly as it sounds, complex fakes can require their own tests. Use discretion and decide as a team where that line is.
Alternatives and trade-offs
One dimension to examine tests on is how large of a scope they test:
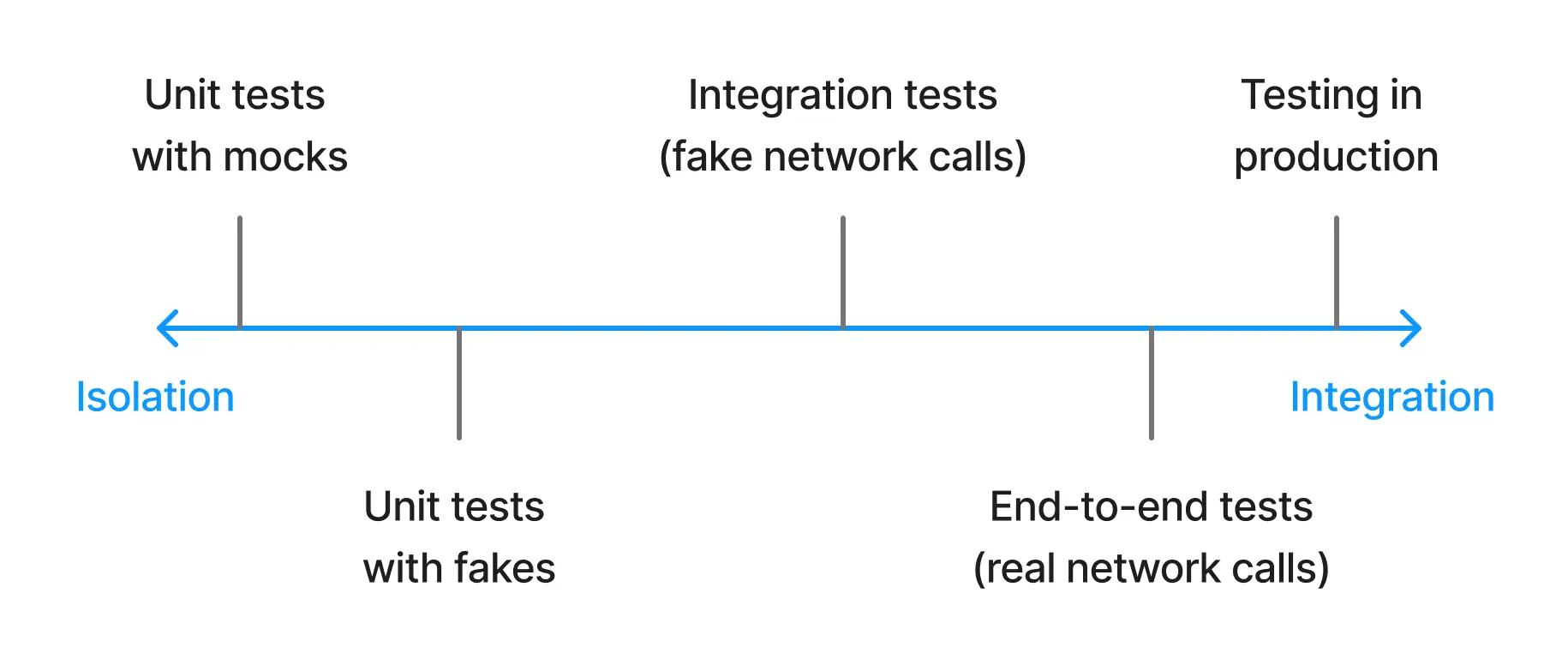
As you can see on this authoritative diagram, using fakes brings our unit tests a half-step towards integration tests, since they’re now testing interactions with their dependencies. This is actually the point: our code doesn’t run in isolation in the real world, so why should it in tests?
One alternative would be to continue down that line of thinking and create full-on integration tests and end-to-end tests. While these are useful and certainly have their place in a test suite, they have some downsides:
- They are slow to run since they usually use real network calls and disk writes
- They are hard to create and maintain since they’re inherently more complicated
- They make it hard to diagnose exactly what caused a specific failure since they test so much at once
On the other side of things, we have our antagonist of this post, the “pure” unit test with mocks. We’ve discussed most of their downsides, but to recap:
- They are so overly specific that they can only catch a narrow set of problems
- They are difficult to write because of their repeated configuration
- They are of questionable value due to their unrealistic environment
But, nothing in this world is perfect, and unit tests with fakes are no exception:
- They require more work upfront to create the fake definitions
- As the fakes get more and more complex, they can require their own set of tests
- Fakes, no matter how meticulously crafted, will never exactly match the behavior of real code, by definition
Conclusion
I strongly believe that, if you’re not already using them in your test suite, you should invest in creating some fakes. Make a team-wide or platform-wide rule that new modules must include a fake version when written, then slowly go back and create definitions for the most-used old modules and start migrating tests. Once you do, you can reach testing nirvana, or some rough approximation of it. Call it a fake nirvana. 😉
If you have thoughts, comments, or just want to tell me I’m wrong, feel free to comment on my mastodon post or send me a message, and I’d be happy to hear it.